AI 비서 만들기 — Claude API + 본인 데이터
이 레슨이 끝나면
- "RAG"가 정확히 뭐고 왜 필요한지 안다 (일반 ChatGPT와의 차이)
- 본인 노트·문서·블로그를 base로 한 개인 AI 비서의 큰 그림을 안다
/v6-ai-assistant스킬을 호출해서 본인 자료 100~1000건 기반 AI 비서를 1개 띄운다
누구에게 추천? — 본인이 오래 쌓은 노트·문서가 있는 모든 사람. 작가/연구자/학생/리더에게 특히.
"RAG"가 정확히 뭐예요?
RAG는 Retrieval-Augmented Generation의 줄임말이에요. 한국어로 풀면 "검색 보강 생성", 더 쉽게 풀면 "AI가 답하기 전에 본인 자료를 먼저 찾아보고 답하는 방식"이에요.
일반 ChatGPT/Claude는 학습 데이터와 본인 질문만 보고 답해요. 본인 독서 노트 1000개, 본인 블로그 500개, 본인 회의록 200개에 대해서는 아무것도 몰라요. RAG는 이 문제를 해결해요. 본인이 "지난주 결정사항 요약해 줘"라고 물으면, AI가 먼저 본인 회의록 중에서 "지난주" 키워드와 비슷한 문서 3~5개를 찾고, 그 문서들을 컨텍스트에 끼워서 답해요.
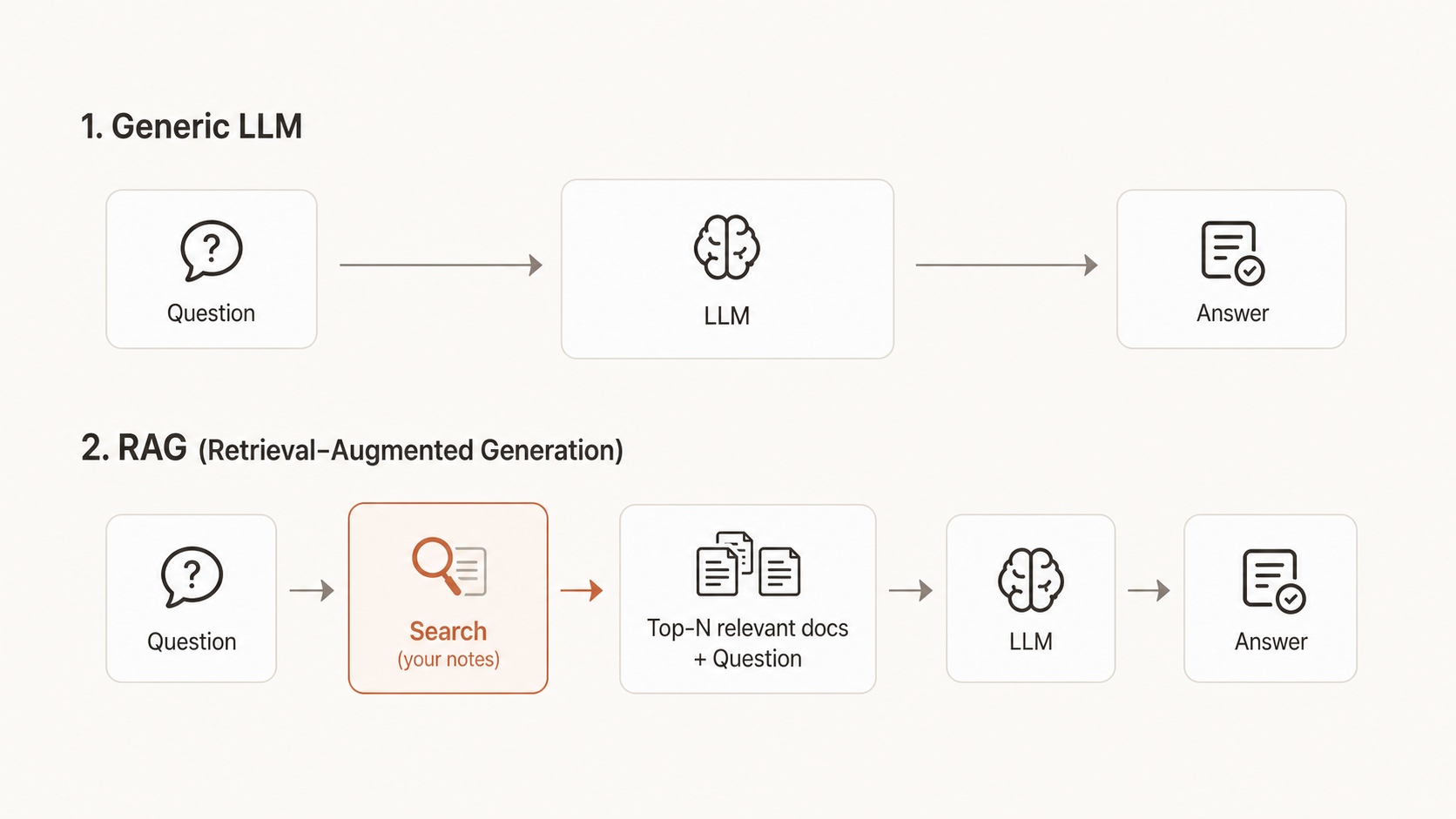
RAG 부품 3가지
| 부품 | 역할 | 대표 도구 |
|---|---|---|
| 임베딩 모델 | 텍스트를 "의미 좌표(숫자 벡터)"로 변환. 비슷한 의미는 비슷한 좌표. | OpenAI text-embedding-3-small / Voyage AI |
| Vector DB | 의미 좌표를 저장 + 검색(가장 가까운 N개 찾기). | Pinecone (클라우드) / ChromaDB (로컬·무료) |
| 생성 LLM | 검색된 문서 + 본인 질문을 받아 최종 답변 작성. | Claude Sonnet/Opus (한국어 최강) |
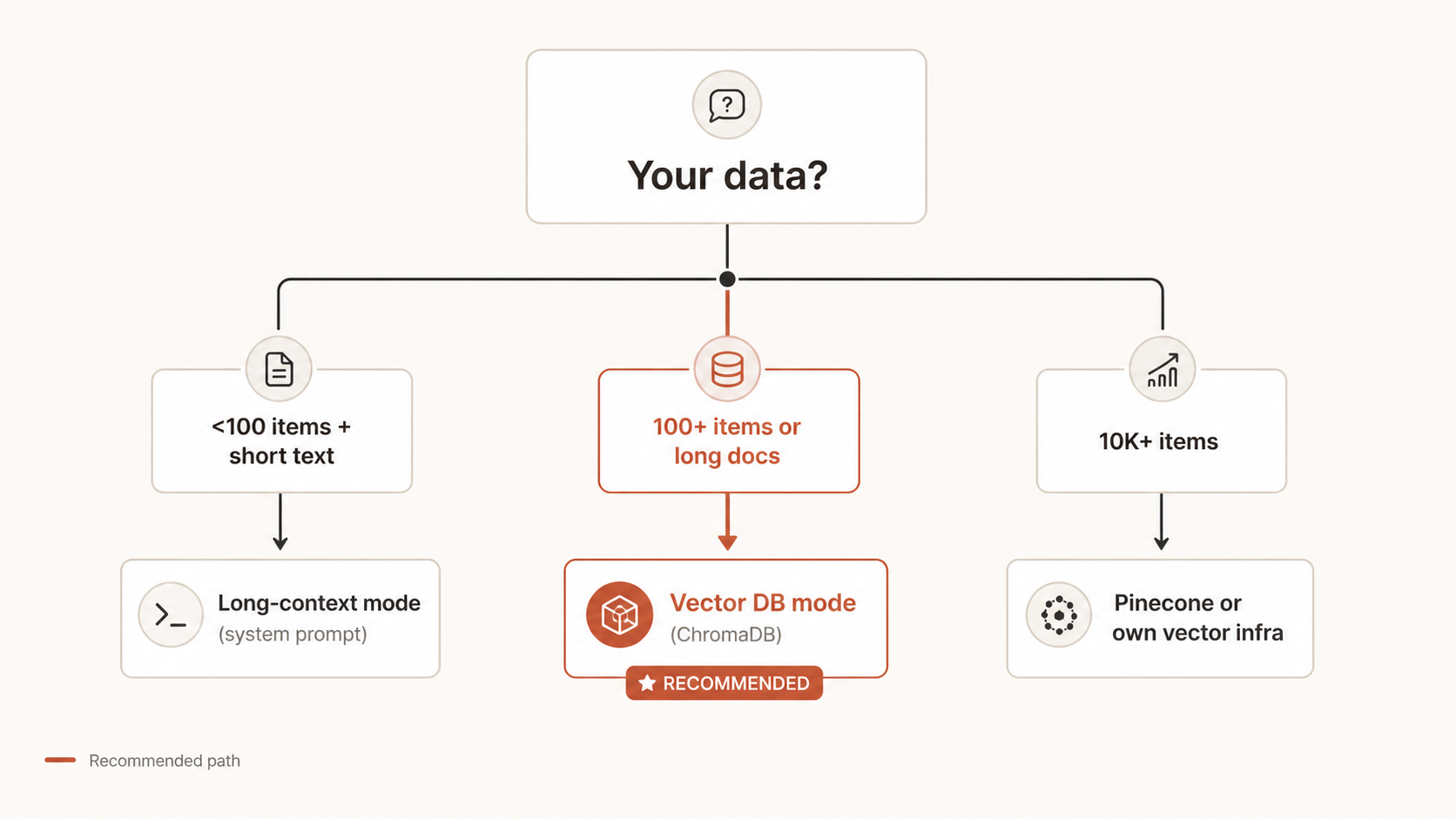
자료가 100건 미만이면 RAG 안 써도 돼요
Claude Sonnet/Opus는 컨텍스트 200K 토큰(약 한국어 100,000자)을 한 번에 받을 수 있어요. 본인 자료 전체가 그 안에 들어간다면 그냥 system prompt에 통째로 넣고 끝. Vector DB 불필요. 이걸 "긴 컨텍스트 RAG"라고 불러요. 입문 추천.
사례 — 본인 자료 기반 AI 비서
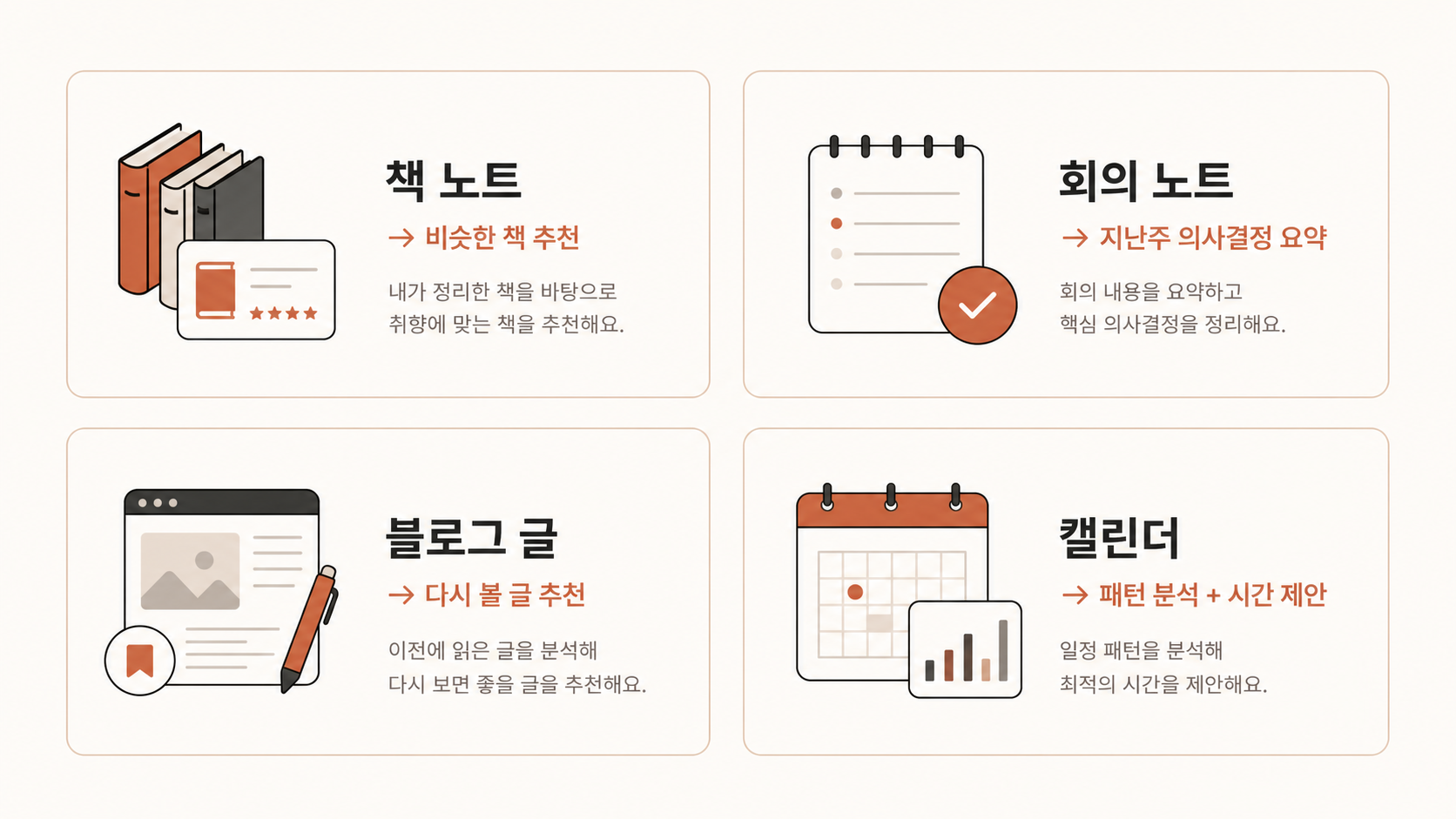
사례 1 — 다독가 D (40세)
10년간 노션에 독서 노트 1200개. "이 책과 비슷한 책 추천해 줘" 또는 "내가 작년에 메모한 자기개발서 3권 요약" 같은 질문에 AI가 본인 노트 기반으로 답. ChromaDB(로컬) + OpenAI 임베딩 + Claude API. 월 운영비 약 1만 원.
사례 2 — 1인 컨설턴트 C (38세)
5년치 회의록 800건 + 클라이언트별 보고서 300건. "X 클라이언트 지난 1년 핵심 이슈 요약" 같은 질문에 AI가 정확히 답. 회의 준비 시간 70% 단축.
사례 3 — 블로거 B (32세)
본인 블로그 글 500편을 base로 "내가 예전에 쓴 글 중 X 주제로 다시 쓰면 좋은 거" 추천. 새 글 아이디어 발굴 시간 80% 단축.
이 스킬을 호출하는 시점
본인 자료가 100건 이상 쌓여 있고, "기억이 안 나서 매번 검색·스크롤"하는 패턴이 반복될 때. 자료가 적으면 그냥 본인이 검색하는 게 빨라요.
Claude Desktop 입력
/v6-ai-assistant
스킬과의 단계별 진행
단계 1 — 자료 위치 + 양 파악
"본인 자료가 어디에 몇 건 있나요? Notion / Google Docs / Obsidian / 마크다운 폴더 등" → 예: "노션 1200건"
단계 2 — 모드 결정 (긴 컨텍스트 vs Vector DB)
자료 100건 미만 + 짧은 글 → 긴 컨텍스트. 100건 이상 또는 긴 문서 → Vector DB.
단계 3 — 자료 추출 + 정제
노션 export / Notion API / 파일 폴더 읽기 등으로 자료를 마크다운/텍스트로 변환. 스킬이 변환 스크립트 자동 작성.
단계 4 — 청크 분할 + 임베딩 + Vector DB 저장
긴 문서를 500자 정도로 쪼개서(청크) 임베딩 변환 → ChromaDB 저장. (긴 컨텍스트 모드는 이 단계 생략.)
단계 5 — 질문 인터페이스 만들기
(a) Claude Desktop에서 매번 호출 / (b) 본인 SaaS 안에 채팅 UI 추가 / (c) 디스코드/카톡 봇 형태(6-3 응용).
단계 6 — 5개 질문으로 정확도 검증
본인이 답을 알고 있는 질문 5개로 테스트. 답이 본인 자료와 일치하면 OK.
긴 컨텍스트 모드 코드 예시 (가장 단순)
app/services/personal_assistant.rb
class PersonalAssistant
def initialize
# 본인 자료를 한 덩어리로 (100건 이하 추천)
@notes = Dir.glob("data/notes/*.md").map { |f| File.read(f) }.join("\n\n---\n\n")
end
def ask(question)
res = HTTP.headers(
"x-api-key" => ENV["ANTHROPIC_API_KEY"],
"anthropic-version" => "2023-06-01",
"content-type" => "application/json"
).post("https://api.anthropic.com/v1/messages", json: {
model: "claude-sonnet-4-5",
max_tokens: 1500,
system: "다음은 사용자의 개인 노트 모음입니다. 이 노트만 참고해서 답하세요.\n\n#{@notes}",
messages: [{ role: "user", content: question }]
})
res.parse.dig("content", 0, "text")
end
end
Vector DB 모드는 위 코드의 @notes를 매번 "질문과 가장 비슷한 청크 5개"로 동적 교체해요.
스킬이 ChromaDB 셋업 + 청크 분할 + 임베딩 변환 + 검색 함수를 모두 자동 작성해 줘요.
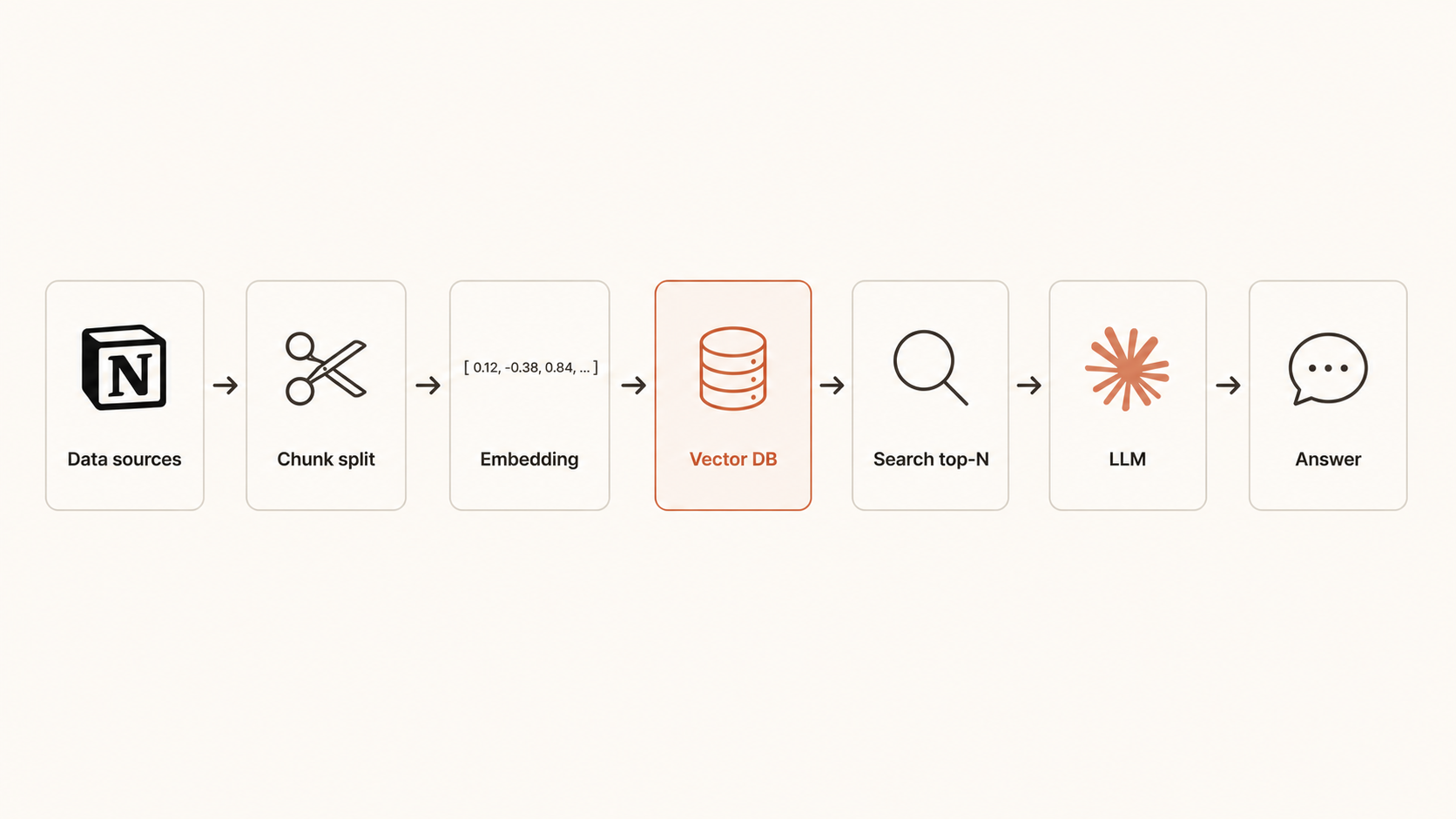
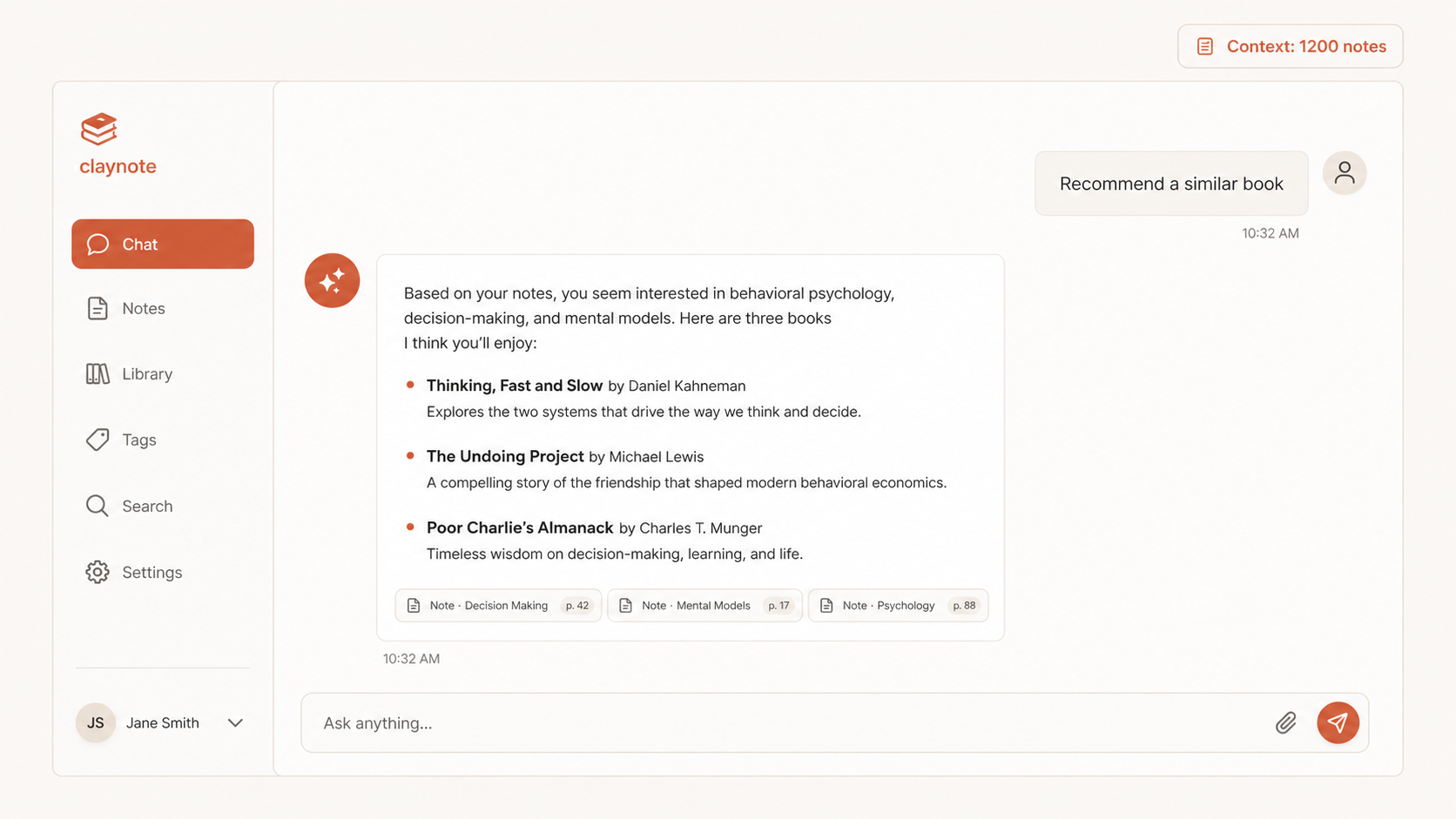
막히는 지점 — 미리 답
① "벡터", "임베딩"이 무서워요
세부 수학은 몰라도 돼요. 핵심은 한 문장: "텍스트 → 숫자 묶음(좌표) → 비슷한 의미는 좌표가 가까움". 그래서 검색이 키워드가 아닌 "의미"로 가능해요. 예: "주말 매출"과 "토요일 수익"이 의미상 가까워서 같이 잡힘.
② 답변 정확도가 낮아요
(1) 청크를 너무 작게 쪼개면 컨텍스트 부족. 500~1000자 추천. (2) 검색 결과 N을 3에서 5~8로 늘려 보세요. (3) "근거가 자료에 없으면 '확실치 않음'이라고만 답하세요" system prompt 추가.
③ Vector DB 운영이 부담돼요
ChromaDB는 본인 PC/서버에서 SQLite처럼 파일 1개로 동작. 별도 서버 불필요. 자료 1만 건까지 충분. 그 이상이면 Pinecone(클라우드, 월 $0~$70).
④ 자료 갱신이 자주 일어나요
ActiveJob으로 매일 새벽 자동 동기화 (6-2 자동화 응용). 새 자료만 임베딩하고 Vector DB에 추가.
완료 체크리스트
- ☐ 본인 자료 위치와 양을 파악했다 (예: 노션 1200건)
- ☐ 모드 결정 (긴 컨텍스트 / Vector DB)
- ☐ 자료를 마크다운/텍스트로 추출 완료
- ☐ Claude API 호출 코드 작성 + 첫 응답 받음
- ☐ 본인이 답을 아는 질문 5개로 정확도 검증
- ☐ 매일/매주 자료 동기화 자동화 설계 (선택)
다음 → 6-6 Hermes 에이전트 소개
여기까지가 본인이 직접 만드는 5가지 활용 사례였어요. 6-6/6-7/6-8은 Vuild가 만들어 둔 심화 도구 3가지 소개예요. Hermes(마케팅) / OpenClaw(분기) / Hyperframes(재사용 프레임). 본인 SaaS의 다음 단계에 도움이 될 거예요.
실습하기
로그인하면 스킬을 실습할 수 있습니다